CFDNet: A Generalizable Foggy Stereo Matching Network with Contrastive Feature Distillation
Zihua Liu, Yizhou Li, Masatoshi Okutomi
Tokyo Institude of Technology
IEEE International Conference on Robotics and Automation (ICRA2024)
Stereo Matching Under Hazing Conditions
The visualization videos that our method compared with other methods. Our proposed CFDNet clearly preserve better structure and continous estimated disparity results in foggy conditions.
Abstract
Stereo matching under foggy scenes remains a challenging task since the scattering effect degrades the visibility and results in less distinctive features for dense correspondence matching. While some previous learning-based methods integrated a physical scattering function for simultaneous stereo-matching and dehazing, simply removing fog might not aid depth estimation because the fog itself can provide crucial depth cues. In this work, we introduce a framework based on contrastive feature distillation (CFD). This strategy combines feature distillation from merged clean-fog features with contrastive learning, ensuring balanced dependence on fog depth hints and clean matching features. This framework helps to enhance model generalization across both clean and foggy environments. Comprehensive experiments on synthetic and real-world datasets affirm the superior strength and adaptability of our method.
Method Overview
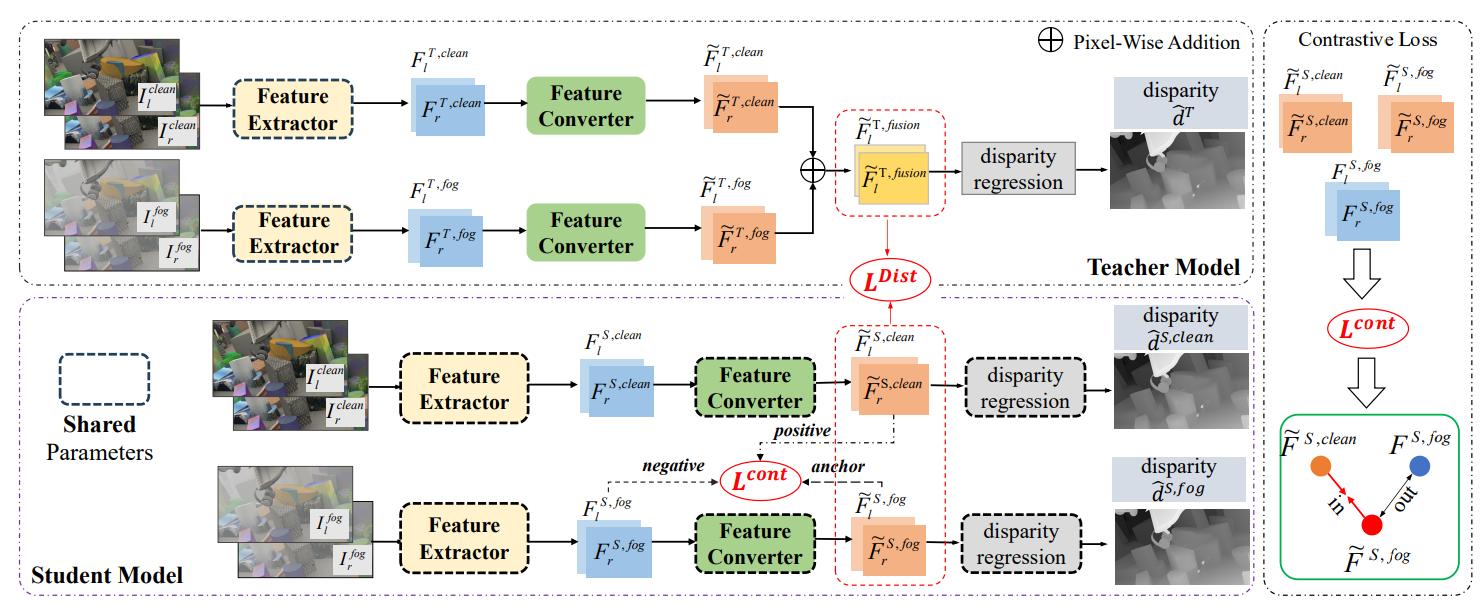
Figure 1. An overview of our proposed CFDNet.
We propose a contrastive feature distillation(CFD) strategy and a network named CFDNet. We discovered that fog does not invariably degrade stereo matching. The fog's thickness can offer valuable depth cues, where we demonstrate its effectiveness in enhancing matching features significantly with our contrastive feature distillation. The whole network consists of a Teacher Model and a Student Model. Specifically, Teacher Model takes pairs of clean and foggy images as input, merging features adapted by an attentive feature converter. The Student Model, having a similar structure, can accept single domain inputs. It benefits from the guidance of the adaptively fused features by the Teacher Model.
Attentive Feature Converter
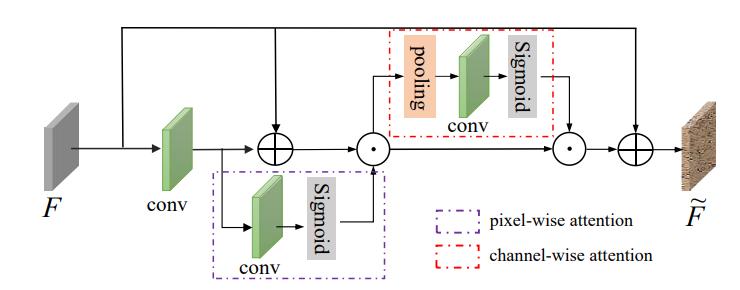
Figure 2. Attentive Feature Converter. A feature aggregation module with pixel-wise and channel-wise attention layers.
Motivated by recent advancements in image dehazing works, such as FFANet and Dark Channel Prior , discrepancies between features extracted from foggy and clean images often manifest in both spatial and channel dimensions, our proposed feature converter takes the initial feature F from the feature extractor as input. It employs consecutive pixel-wise attention (PA) and channel-wise attention(CA) modules to synergistically modify features in spatial and channel dimensions. It helps the teacher model to capture both clean and haze usage information.
Loss Functions
Loss Function for the Teacher Model:
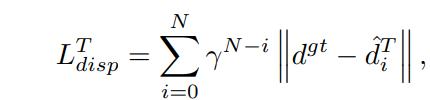
The Teacher Model is trained using the ground truth disparity map, adhering to the sequential loss from RaftStereo, Here N is 12,which is the total iteration numbers.
Loss Function for the Student Model::
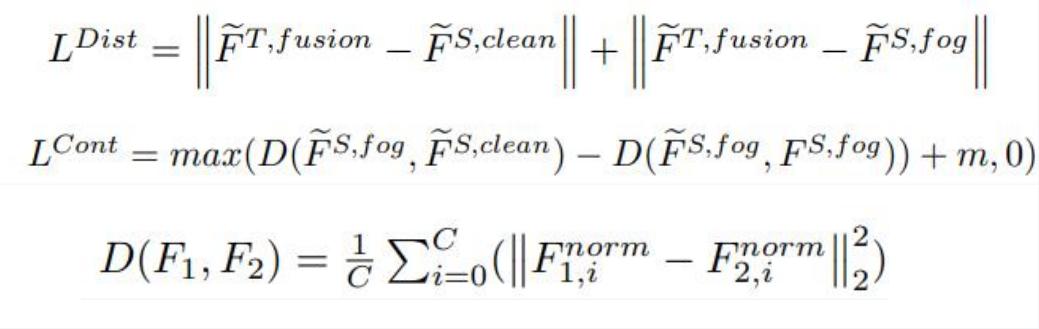
Concretely, for the feature distillation, we minimize the L1 distance between the teacher feature and the student features. Regarding contrastive learning, we use the Triplet loss, where the m is the distance threshold which in our case equals 1.0.
Quantitative Results
We evaluate our methods on multiple public benchmark datasets including SceneFlow, KITTI, and PixelAccurateDepth. As the training of the proposed network requires pair clean and foggy images, we use the atmosphere scatter equation to render the foggy using the ground-truth disparity for SceneFlow and the KITTI dataset.
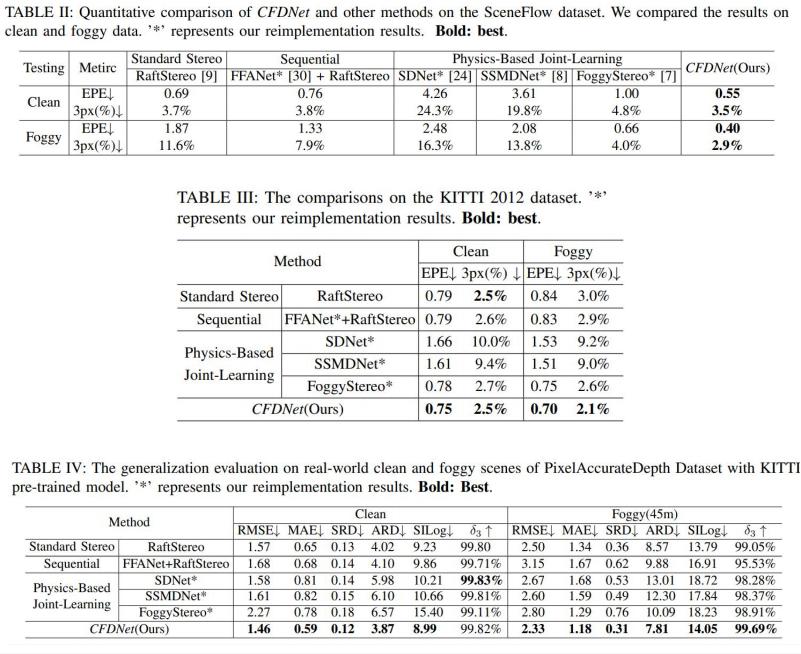
Qualitative Results
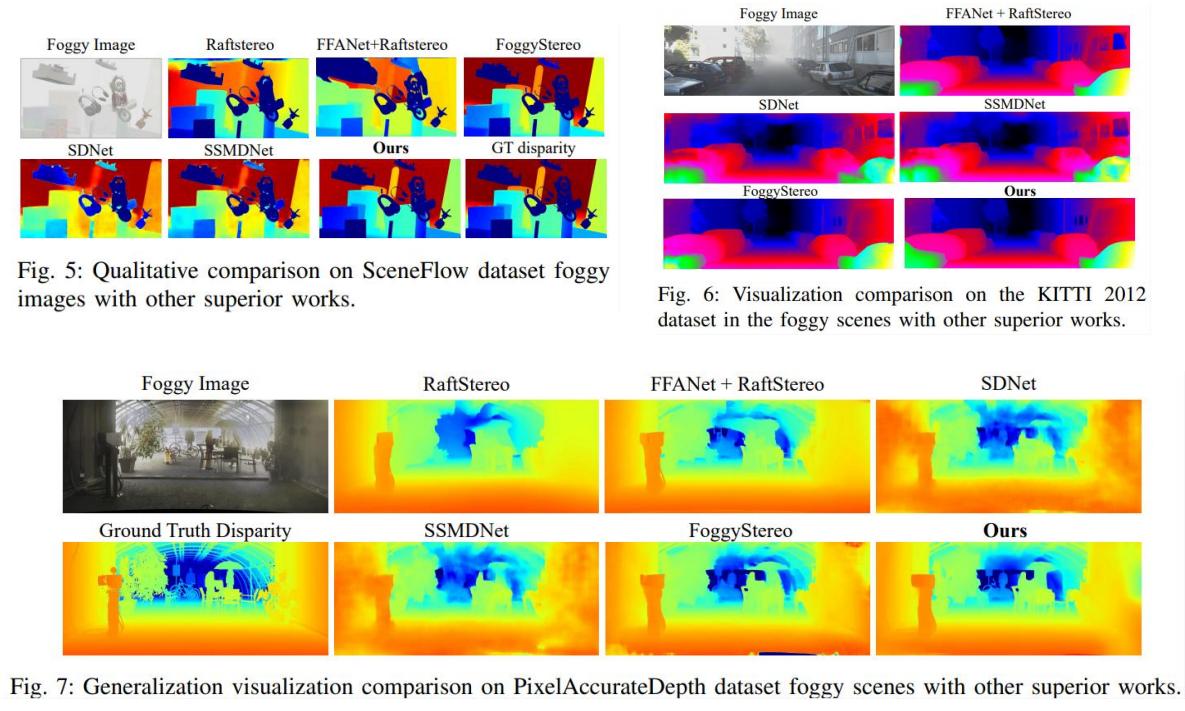
Qualitative Comparsion on SceneFlow and KITTI and PixelAccurate Dataset with other SOTA Methods.
Publications
CFDNet: A Generalizable Foggy Stereo Matching Network with Contrastive Feature Distillation
Zihua Liu, Yizhou Li, Masatoshi Okutomi
IEEE International Conference on Robotics and Automation (ICRA2024)
Contact
Zihua Liu: zliu@ok.sc.e.titech.ac.jp
Yizhou Li: yli@ok.sc.e.titech.ac.jp
Masatoshi Okutomi: mxo@ctrl.titech.ac.jp
     |